
24/03/25
1교시
주제 : Compute Shader (CS) 작성 완료 맟 기능 마무리
작업 내용 :
ParticleTickCS 클래스 코드 왼성 및 Particle 객체 움직여보기
Compute Shader의 스레드/그룹 개수 :
Compute Shader는 멤버로 "그룹 당 스레드 개수" 멤버와 "그룹 개수"멤버를 가지고 있다.
그룹 당 스레드 개수의 경우 생성자 호출시 들어오는 인자로 값이 초기화되며, 그룹 개수는 CalculateGroupNum() 함수에 의해 업데이트 된다.
CalculateGroupNum() 함수의 경우 자식 객체에서 오버라이드한다.



가로(x)방향으로 32개의 스레드를 지원하도록 설정했으며,
ParticleTick 셰이더 코드와 셰이더 실행시키는 부분의 싱크를 맞춰 줌
"그룹 개수(m_GroupX) 는 "Particle 버퍼에 들어가 있는 Particle 원소 개수 / 그룹당 스레드 개수(32)" 로 구해준다.
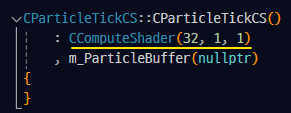


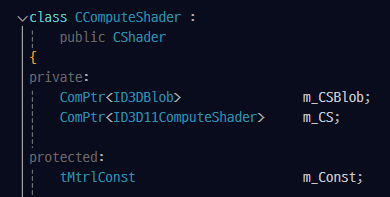
ParticleTickCS 클래스 :
ParticleTickCS 클래스는 Particle의 데이터를 업데이트(갱신) 시켜주는 역할을 한다.
Particle 을 관리하는 ParticleSystem 클래스의 finaltick() 함수에서 ParticleTickCS 클래스의 함수들을 호출한다.
- SetParticleBuffer() : Particle 업데이트용 CS에서 업데이트 시켜줄 버퍼를 설정해준다.
- Execute() : Particle 관련 데이터를 particletick 셰이더 파일에 전달 후 CS를 실행시켜준다.
finaltick() 함수는 매 프레임마다 호출되는 함수로 tick() (=update()) 함수에서 갱신된 데이터를 바탕으로 마무리 작업을 해주는 기능을 한다.


ParticleSystem에서 호출하는 Execute() 함수는 ComputeShader 클래스에서 정의한 함수이며,
Execute() 함수 내부에서 호출되는 Binding(), CalculateGroupNum(), Clear() 함수는 자식객체들이 재정의한 함수들이며, 이를 ComputeShader 클래스의 Execute() 함수 내부에서 호출한다.
Binding() :
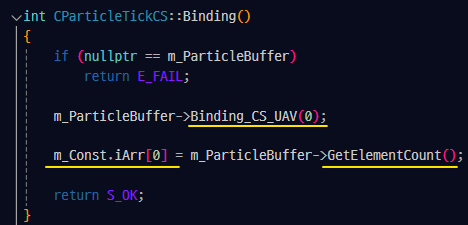
ParticleTick 클래스에 정의된 m_ParticleBuffer는 해당 클래스에서 CS를 통해 데이터를 업데이트 시켜줄 버퍼다.
해당 버퍼가 세팅 되어 있지 않다면 Binding() 함수는 바로 종료되며, 반환값 E_FAIL에 의해 assert()가 발생한다.
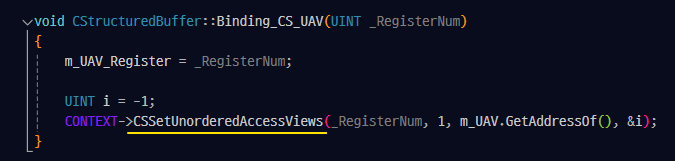
업데이트 시켜줄 버퍼를 u레지스터에 바인딩해준다.
버퍼에 들어있는 원소의 개수를 상수버퍼의 iArr[0] 원소에 담는다.
이때 원소의 개수는 생성가능한 Particle 객체의 "최대 개수"를 의미한다.
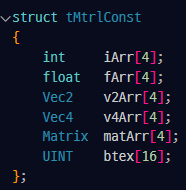
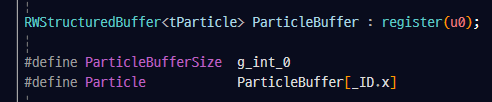
해당 값은 이후 아래의 코드에 의해 셰이더 코드에 전달되고, 해당 값을 CS에서 참조하여 사용한다.

particletick 셰이더 코드에서 참조하는 값들
CalculateGroupNum() :
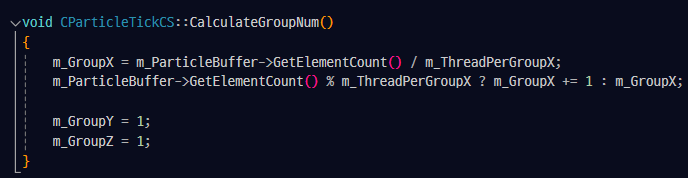
버퍼에 들어있는 원소의 개수(생성 가능한 최대 파티클 개수) 를 "그룹당 스레드의 개수" 로 나눠준다.
x그룹의 개수만 계산하는 이유는 1차원으로 사용할 것이기에 y,z 는 1의 값을 가진다.

refer :
병렬처리 기법 2
이전 포스팅에서는 CPU의 작업을 GPU로 전환하는 과정을 설명했었다. 여기서 이제 좀 더 효율적으로 GPU 에게 작업을 맡겨보자 현재 CubeShader.shader 에서 회전 행렬과 이동 행렬을 연산하고 있는데, G
shkim0811.tistory.com
m_ParticleBuffer->GetElementCount() % m_ThreadPerGroupX ? m_GroupX += 1 : m_GroupX;해당 코드는 원소의 개수가 그룹당 스레드의 개수와 딱 나누어 떨어지지 않는경우 하나의 그룹을 추가적으로 생성해서 나머지 원소들도 그룹에 넣어주기 위한 추가 연산이다.
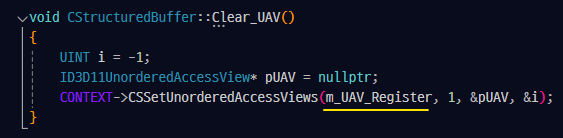
Clear() :
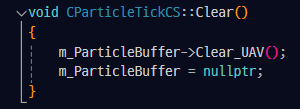
particletick 셰이더 코드에서 사용하고자 바인딩해줬던 값들을 비워주는 작업을 한다.
Clear_UAV() 함수는 아까 particle buffer의 데이터를 register에 Binding 할때 호출했던 CStructuredBuffer::Binding_CS_UAV() 함수에서 저장했던 m_UAV_Register(=0)의 번호에 해당하는 레지스터를 비워진 값으로 대체하는 작업을한다.
파티클 움직이기 :
particletick 셰이더 코드에서 particle의 위치값을 업데이트 시켜준다.
이미 위의 과정을 통해서 생성될 particle들에 대한 데이터(ParticleBuffer : register(u0))와 최대 생성가능한 파티클 개수(g_int_0)에 대한 정보를 얻어왔다.


그런데 모든 파티클은 CS에 의해서 동시에 정보가 처리되는데 어떻게 각 스레드가 Particle 버퍼에서 각자가 담당할 각 원소를 하나씩 불러올 수 있을까?
CS_ParticleTcik() 함수의 인자를 보면 "SV_DispatchThreadID" 키워드를 볼 수 있다.
이는 스레드 하나가 실행될때마다 발급되는 고유한 이이디로 해당 매개변수(int3 _ID)를 통해 스레드별 고유 인덱스를 받아올 수 있다.
32개의 스레드를 실행하라고 명령했다면 _ID에 0~31 까지의 값이 전달된다.
해당 값을 ParticleBuffer의 인덱스 값으로 사용해서 스레드가 담당할 각 Particle에 대한 정보를 받아와 위치값을 초당 100pixel 이동하도록 위치값을 갱신해준다.

2교시
주제 : Particle Update 괸련 문제 해결 (1)
작업 내용 : 한 프레임에 생성되어야 할 SpwnCnt 계산하고 CS로 넘겨줌, 스레드 간의 동기화 진행 중
문제점 :
Particle 데이터 Update()에 2가지 문제점이 있다.
- 비활성화된 파티클중 몇개만 활성화 시키고 싶은데 모든 파티클이 활성화된다.
- 랜덤하게 몇개의 파티클만 활성화 시키고 싶은데 랜덤하게 선택하는 방법?
오늘은 1번 케이스에 대해서만 다룬다.
왜 전부 활성화 되는가? :
다중 스레드(병렬) 작업을 하기에 모든 스레드가 조건을 동시에 충족하기 때문이다.
예를 들어서 생성가능한 개수가 1개라고 하면 모든 스레드가 해당 조건을 만났을때 당시에는 생성된 개수가 0개 이기에 모든 파티클이 해당 조건을 충족하게되면서 활성화 되어버린다.
즉, 스레드 동기화 처리를 해줘야한다.
Spawn Count :
셰이더가 파티클 생성작업을 하기 위해선 초당 생성되야하는 파티클의 개수를 알아야한다.
초당 10개의 파티클이 생성되어야 한다면 60 프레임의 프로그램에선 6프레임당 1개의 파티클을 생성해줘야한다.
즉, 파티클이 생성되어야 하는 타이밍의 프레임에 도달하면 셰이더는 파티클 생성 카운트를 받아 해당 개수에 맞게 파티클을 생성한다.
해당 작업이 수행되기 위해선 파티클 생성 카운트와 전달 과정을 설계해야하는데 해당 작업을 해보자.
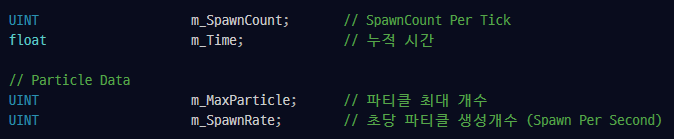

1초 를 "초당 생성되어야 할 파티클의 개수"로 나눠주면 1개의 파티클이 몇초의 간격으로 하나씩 생성되어야 하는지 알 수 있다.
float Term = 1.f / (float)m_SpawnRate;m_Time 은 매 프레임마다 DeltaTime 을 누적하는데 이 누적시간은 파티클 생성의 조건으로 사용된다.
m_Time += DT;
if (Term < m_Time) { ... }"조건 (누적시간 > 파티클 생성 간격)" 을 만족하였다고 하여 파티클을 하나만 생성해선 안된다.
예를 들어 초당 120개를 생성해야한다고 하면 60프레임의 프로그램에선 한 프레임당 2개의 파티클을 생성해줘야한다.
만약 조건을 만족하면 파티클을 하나만 생성하게 했다면 생성하려고 했던 파티클의 절반만 생성할 수 있게 된다.
때문에 해당 프레임에서 생성해야하는 파티클의 개수는 "누적시간 / 파티클 생성 간견" 으로 계산해줘야한다.
float Value = m_Time / Term; // 해당 프레임에서 생성해야하는 파티클 개수
m_SpawnCount = (UINT)Value;
m_Time -= (float)m_SpawnCount * Term; // 누적시간 초기화()
스레드 동기화 :
"atomic function"
해당 함수들을 사용하면 스레드간 동기화하여 값을 수정할 수 있다.
refer :
Atomic Functions - Win32 apps
To access a new resource type or shared memory, use an interlocked intrinsic function. Interlocked functions are guaranteed to operate atomically. That is, they are guaranteed to occur in the order programmed. This section lists the atomic functions.
learn.microsoft.com

InterlockedAdd() :
void InterlockedAdd(
in R dest,
in T value,
out T original_value
);여러개의 스레드 중 하나의 스레드가 해당 함수를 만나면 다른 스레드들은 해당 함수가 종료될때까지 더 이상 진행되지 못하고 대기하게된다.
하지만 해당 함수를 사용할 순 없다.
왜냐하면 하나의 스레드가 해당 함수를 이용해 생성가능한 Particle의 개수를 하나 줄여도 조건을 검사하러 가는 도중에 다른 스레드들이 Particle 생성가능 개수를 줄여버려서 결국 모든 파티클이 활성화되지 못하게된다.
InterlockedExchange() :
void InterlockedExchange(
in R dest, // 목적지, 원래 값
in T value, // 변경될 값
out T original_value // 원래 값 받아줄 곳
);Add의 한계를 해결 할 수 있는 방법은 Exchange 함수를 사용하는거다.
해당 함수는 내부적으로 값 변경을 해준 후 변경되기전의 값을 마지막 인자로 들어온 곳에 저장해준다.
세번째 인자를 통해 받은 값을 활성화 여부 조건문으로 사용하면 Add의 한계점을 해결할 수 잇다.
Next Note
AR50_ClassNote_5
24/03/26 1교시 주제 : 작업 내용 : 2교시 주제 : 작업 내용 : Next Note
coder-qussong.tistory.com
'DirectX11 > AR' 카테고리의 다른 글
| AR50_ClassNote_6 (0) | 2024.03.28 |
|---|---|
| AR50_ClassNote_5 (0) | 2024.03.26 |
| AR50_ClassNote_3 (0) | 2024.03.23 |
| AR50_ClassNote_2 (0) | 2024.03.22 |
| AR50_ClassNote_1 (0) | 2024.03.21 |